
Hashing is an arrangement of data to manage and identify uniquely. Hash function, Hash Table, Hashing, Rehashing, Consistent hashing, Hash Ring are the various terms which need to be learned, in order to implement hashing efficiently. Today we are going to discuss each one of these, with different examples we will check problems of rehashing, challenges in distributed hash tables and its solutions.
Hashing in data structure is a technique that’s used to uniquely identify a selected object from a collection of comparable objects. Hashing is a crucial arrangement which is meant to use a special function called the Hash function which is employed to map a given value with a specific key for faster access of elements. The efficiency of a hash function further decides the efficiency of mapping.
- Hashing algorithm example
- Hash Function
- Hash Tables
- Hashing
- Rehashing
- Hash Table at Scale
- Distributed Hash Table
- Distributed Hash Tables and Rehashing Problems
- Consistent Hashing
- Hash Ring
- How Consistent Hashing Works?
- Add a new server to the hash ring
- Removing a machine from the ring
- Non-Uniform Distribution of keys
Some samples of how hashing can be applied in our lives include:
- In Schools, every student is assigned a unique roll number. Using this roll number, we can identify the student and retrieve his information.
- At airports, every flight is given a unique number. Using this unique number we can extract all information like when this flight will arrive, depart etc.
In these both examples the flights and students were hashed to a unique number.
Hashing algorithm example
Suppose you want to store a large set of objects (imagine Facebook posts as an example). You want to assign a unique key to every object, so you can search it directly. You can use a basic array data type where the sequence number can be key and linked with a unique post. The problem here would be scaling. If your array size grows too big, at some stage long keys could not be used for index. This is the point where you need to start using hashing data structure.
In hashing data structure, with the help of hash functions, the large keys are easily converted to small keys. The objects are stored using these keys in the data structure, this is called a hash table. The motive of hashing data structure is to uniformly distribute entries (key/value pairs) across the storage.
Every object is assigned a unique key, which is basically a hash key. By using this hash key, you can access the object in O(1) complexity. When we search an object using a hash key, the hash table calculates the index internally that further tells where an object can be present.
Hash Function
A hash function is a function which is used for mapping the data of arbitrary size to fixed-size values. The fixed-sized values returned by a hash function are called hash values, hash codes, digests, or just hashes. The values are accustomed to index a fixed-size table called a hash table. The usage of a hash function to index a hash table to address scatter storage is called hashing.
A hash function takes an input as a key, which is related to a datum or record and accustomed to identify it to the info storage and retrieval application. The keys could also be fixed length, like an integer, or variable length, sort of a name. In some cases, the key’s the datum itself. The output of hash table will be a hash code used for indexing a hash table holding the information or records.
A hash function mainly perform three functions:
- Convert the variable length keys into fixed length (usually machine word length or less) values, by minimizing them by words or other units employing a parity-preserving operator like ADD or XOR.
- Shift the bits of the keys in specific order that the resulting values are uniformly distributed over the key range.
- Map the key values to the objects.
Hash Tables
A hash table is basically a data structure which implements an associative array of abstract data type, a structure that maps keys to values. Hash function is used by a hash table to calculate an index, also known as hash code, into arrays or buckets, from which the specified values can be found. When data lookup is required, the keys are hashed and the resulting hash represents where the corresponding value can be found.
Hashing
Hashing is a conversion process of a given key into another converted value. The hash function is called to find the new value, consistent with a special logic. The results of a hash function are called hash values or simply a hash.
A good hash function has one-way hashing algorithm, which means, the hash can not be converted back to the previous key.
Rehashing
The process of re-calculating the hash of already stored data (Key-Value pairs) and to migrate these to another bigger size hash space when threshold is crossed/reached, is called Rehashing
Rehashing of a hash map is performed when the amount of data within the map reaches the utmost threshold value. According to Java specification 0.75 is the great ratio value for a Map and the default initial capacity is 16. Once the amount of entries reaches or crosses 0.75 times the capacity of map, the complexity gets increased. To reduce the complexity, the size of Map is doubled and all existing entries are hashed again and distributed within the new doubled size. During this case, when the amount of elements is 12, rehashing occurs. (0.75 * 16 = 12).
Why is Rehashing required?
Rehashing is needs to be performed whenever a new key value pair enters into a map, the load factor gets increased and because of which complexity also gets increased. With increased complexity the HashMap won’t have constant O(1) time complexity. So rehashing is required to distribute the data across the hashmap, to reduce both load factor and complexity. Once After rehashing is performed existing items may get fall within the same bucket or different bucket. In following example, when the amount of elements is 5, rehashing occurs. (0.75 * 7 = 5.25).

Hash Table at Scale
With huge volume of data we can face both performance issues as well as hardware limits. To handle such issues, we need to distribute the data over multiple machines. Distribution schemes can be decided on the nature of the business requirements. You may need exact replicas of data, distributed servers with range, distributed over geography etc.
Once we decide to distribute our data, then the next question arises, how the application will identify that which data lies on which server. For this we have to maintain a table or a kind of list of all servers with their range/ geography’s data, this is called as Distributed Hash table.
Distributed Hash Table
A distributed hash table (DHT) is a decentralized storage system that performs lookup and store schemes details almost like a hash table, storing as key-value pairs. The values mapped against keys in a DHT, has servers and a hash range typically, this represents which server is responsible for managing which hash range.
Each node in a DHT is liable for keys along-side the mapped values. Any node should be efficient to retrieve the value related to a given key.
Distributed Hash Tables and Rehashing Problems
This distribution scheme is very straightforward , intuitive, and works very well. Until the amount of servers don’t change. What will happen if one among the servers becomes unavailable or crashes? Keys should be redistributed to manage the missing server, of course an equivalent applies when a new server is added to the list. Hash keys have to be redistributed to incorporate the new servers. So if we call hash function with changed number of servers then result may get differ, to manage this issue we have to do rehashing of whole data on all server. Therefore even if one server is removed or added, all hash keys have to be rehashed.
Consistent Hashing
Consistent hashing handles the rehashing problem by implementing a distribution scheme which doesn’t directly tied to the count of servers.
Consistent Hashing is a distributed hashing scheme which works independently of the number of servers list or objects present in a distributed hash table by assigning these a location on an abstract circle, or hash ring. This enables us to scale servers and objects , without affecting the general system.
Hash Ring
In-consistent hashing, the hash function works without using the count of nodes/servers. All servers are assumed to be present on a circle, where hash code is used to locate the server, which can handle the request of that hash code. From any server present on the circle, it can be identified that request will be processed from next server, previous server or itself the current server. This virtual circle is known as Has ring.
How Consistent Hashing Works?
You can create a hash function using any kind of logic, generally a hash function will take input of the hash key and returns the results. For example, a hash function can be created like this,
position = hash(key) % (2^n )
Finding the position of keys and servers in the ring:
- To find the position of any server, we can take the hash of Ip address of that server and then calculate its position using the above mentioned hash function.
- Find the hash for each known key and find its position. Now place all hashes and servers at their particular positions over the ring.
- Map keys and servers, which have the same hash value as that of the key( server hash value == key hash value).
- In case the key hash value doesn’t map to any server, the key will be mapped to its nearest server in the clockwise direction.

Add a new server to the hash ring
If we want to add a new server names as “machine 4” and assuming its hash value lies between machine 1 and machine 3.
For adding a new machine, we don’t have to rehash all the key values, instead rehash only those keys which lie in between machine 3 and machine 1. On average in real-time, if you have n machines and k keys, you have to rehash only k/n keys. This is a very significant improvement over the earlier basic hashing technique.

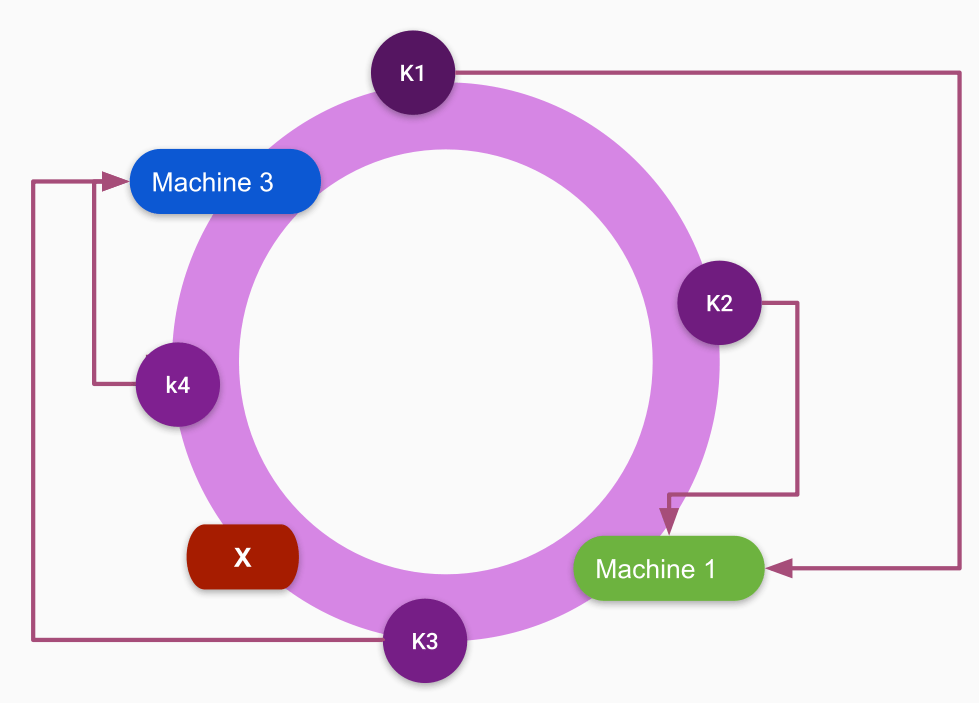
Removing a machine from the ring
In case a machine gets crashed or goes down then you have to rehash only keys stored on that machine only. The keys are moved to its clockwise neighboring server. In following example, if red(X) represents a machine is down then its mapped keys K3 are moved to machine 3.
Non-Uniform Distribution of keys
With Hash ring usage, there can be a problem if hash function doesn’t distribute the keys efficiently. This is a non-uniform hashing problem i.e, the majority of keys get mapped to a single machine or near to the single server. This is not ideal situation as one machine has large number of keys mapped as compared to all other servers.

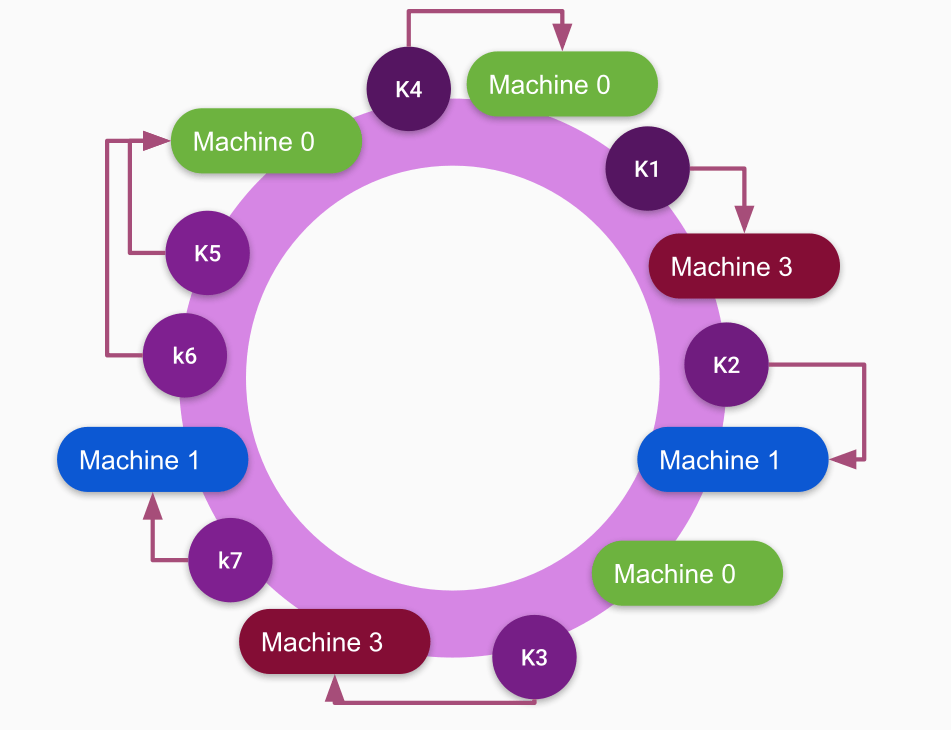
To handle this situation we can introduce more replicas of each server/ machine and each machine’s replica gets hashed to a different hash value, which looks like more new machines are placed on the ring at random positions. if we increase the number of these replicas, the distribution will become more & more uniform.
For example, if we have 3 machines then we can map the keys to 3 machines only. If we create replicas of these machines as shown in diagram, we will have virtually many machines and load can be divided within machines, as multiple range of virtual machines will point to original machines.
Improving performance Further
Gossip protocol is very efficient in managing large scale hashing data.
Uber has implemented the gossip protocol with consistent hashing, the advantage of combining these two is huge. Incoming data request can be sent to any machine without checking the correct machine to handle requests. Each machine can work independently and every Machine knows which machine is responsible for which Hash range.
When a data request comes to any machine on ring, then either it has data or not. In the first case, if data is present on the that machine then the request is processed. if data is not found on that machine, then that request is forwarded to that particular machine which has should have this data. It helps in reducing the processing time of request and request follows the minimum path in the hash ring.


You must be logged in to post a comment.